ElasticSearch Cluster: Configuration & Best Practices
I was recently working on setting up an elasticsearch cluster with apache whirr. Setting up a cluster is one thing and running it is entirely different. Running a cluster is far more complex than setting one up. Things are no different for an elasticsearch cluster. There are several things one needs to be aware of and take care of. Some of such things with ES cluster are:
- Type of nodes in the cluster: Master, Data, Controller, Load Balancers
- Picking up the right configuration - Initial number of machines
- Number of shards
- Number of replicas
- Number of indexes
- Loading initial data set into the cluster: how to make it fast?
- Index Size
ElasticSearch Node Types
Even though elasticsearch documentation talks about a Node, it is not very clear and helpful. It just talks about making a node non-data node. In reality one can have following possible node types in a ES cluster:
- Master and Data - This is the default setting. A node stores data and is capable of becoming a master node.
- Only Master - This is a master only node meaning it can work towards cluster related tasks such as shard allocation in the event of new machine availability and/or machine unavailability (instance failure).
- Only Data - This node can only store data. This is a worker node which just work on indexing data and returning search results.
- No Master and No Data - This node never stores any data and never becomes a master, it works as a load balancer. It accepts incoming query requests and routes to a data node. Fetches data from nodes, aggregates results.
As you may have guessed, this is controlled by 2 values in the elasticsearch.yml file in config directory.
node.data: true
node.master: true
Another important setting is http.enabled. When this is set to true, a node provides an HTTP transport. What that means is it provides a API access over http. Now with above four node types, one can create data only nodes and disable HTTP transport. By doing that, we make sure that the data nodes are not doing any other work than just indexing and performing queries. Internal communication between nodes happens with a module called Transport.
In case, one goes ahead with a no master and no date node i.e. load balancer node; such a node passes queries to available data nodes in a round robin fashion. This is not be confused with AWS load balancers. This is an ES mechanism to query all available data nodes. In case of heavy traffic, all queries would never go to one single node with this setup. This node type can also be achieved by setting node.client to true. This was also discussed here.
Getting Configuration Right
Another key question comes up is how many machines to start with? Should we start with 2 or 10? ElasticSearch does provide fantastic facilities in terms of automatic shard allocation. But does that mean we can start with 2 machines and scale upwards up to 100 or even more? The answer is, as always: it depends.
Shards
Generally one needs to plan according to future data growth. Going from a 2 machine cluster to 100 machine cluster in a year or two would sound like huge gaps in understanding data growth. The progression, if at all, would naturally be painful because of wrong starting point in terms of number of shards on 2 machine cluster assuming that a 2 machine cluster would have non planned less number of shards.
Based on the discussion here, it is important to get the starting point correct. Have enough number of shards even when they may seem like a lot for the current situation. As data grows, one can add more nodes to the cluster and since there were more shards then number of nodes in the cluster, some shards would be allocated to new nodes hence reducing workload on some nodes.
Shards are defined at index creation time and they cannot be changed dynamically. Number of shards dictate index creation performance.
Replicas
Replicas can be defined dynamically. One can change number of replicas after creating an index first. Number of replicas dictate search performance and cluster availability. On adding new nodes elasticsearch would automatically assign some shards and replicas to a node.
Lets see an example of 3 node cluster, one node acting as a load balancer and other two just as data nodes.

The data nodes have http.enabled set to false too. Therefore, the machine with no data acts as the entry point into the cluster. All queries go through this machine. If we now add say two machines to this cluster, it resized itself to below configuration. This is because we have a replication factor of 1.
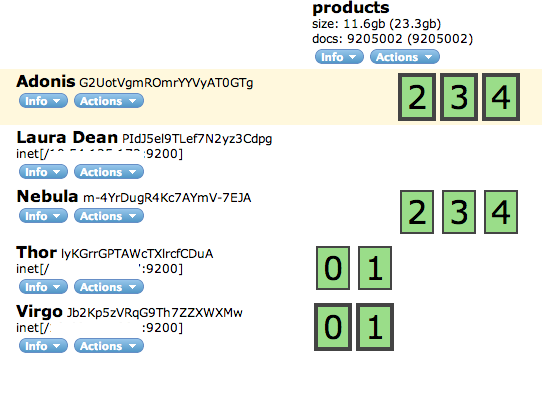
New nodes have been assigned two shards each, one being active and another replica. What happens if we take one node down?
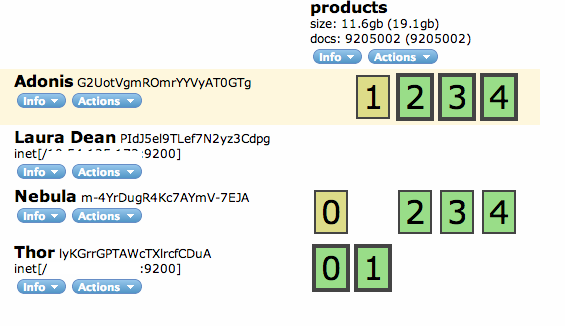
The cluster reassigns shards hold with the down node to other nodes. In this case assigns shards 0 and 1 back to the original machines. During the time shard relocation is happening one may experience some slowness in query performance as data, potentially huge, is being moved.
Indexes
Number of indexes depends on the application in question and related design. Generally putting too much data in a single index would not be optimal. For datasets such as logs, its easier to see data going into daily/monthly indexes. With other data sets, one would need to understand the data, processing needs and devise a methodology to define indexes e.g. one index per client.
While creating multiple indexes, it would be beneficial to define how many shards a single node holds because there is a finite amount of data one node can hold.
Loading Data into ElasticSearch Cluster
ElasticSearch provides several client libraries including one for Java, Python. How fast one can load data into a ES cluster depends on several things:
- Client Lib used, java would outperform python (in theory)
- Document (single row) size being indexed
- Node configuration
I did some tests with the python client. Some of the learning are: - Always use batch mode to insert data, its faster.
- Disable replication while indexing
- Have enough memory on ES nodes, assign half of available memory to ES
- Tweak batch size to arrive at an optimum number
- Loading data with multiple threads may not be beneficial.
I had used two ES nodes each with 16 GB of RAM, 8 GB assigned to ES. I used 5000 as a batch size for a document size of ~1.5 KB. I could store a batch of 5000 documents in about 1.5-3 seconds. Mostly around 1.5-2 seconds.
MySql, did you say MySql?
If your input data happens to be in mysql, getting data fast from it would dictate your indexing performance. If the data is in several million records, doing a normal pagination to get data would be slow. Queries like below:
select * from mytable order by col1 Limit 10000,2000
would take ages as it needs to look into all of millions of records. A workaround would be fire a query like below:
select * from mytable where id>10000 order by col1 Limit 2000
This query would perform far better to return results. This is assuming we have such an id column in the table, if not create one in the same table or create a new sequence table to hold a primary key and an auto incremented id field.
Index Size
Storing the indexes without any compression would take lot of disk space. For my tests, with close to 9.2 million records the index took ~ 18.3 GB. With compression enabled (available only in version > 0.19.5) it came down to 11.6 GB. That is a saving of ~30%. The setting that one needs to put up in elasticsearch.yml is:
index.store.compress.stored: true
index.store.compress.tv: true